はじめに
人工知能(AI)技術の急速な発展に伴い、高性能なGPUリソースへのアクセス方法も多様化しています。特に機械学習やディープラーニングのワークロードを実行する場合、適切なインフラストラクチャの選択は重要な課題となります。本記事では、クラウド型AIサービスとベアメタル型のGPU搭載サーバーホスティングサービスの違い、それぞれのメリット・デメリット、そして様々なユースケースにおける最適な選択について詳しく解説します。
クラウド型AIサービスとベアメタル型GPU搭載サーバーの違い
クラウド型AIサービスとは
クラウド型AIサービスとは、Amazon SageMaker、Google VertexAI、Microsoft Azure Machine Learningなどのクラウドプロバイダーが提供する、仮想化環境上で動作するAI開発・実行環境です。これらのサービスでは、AIモデルのトレーニングや推論に必要なGPUリソースを、必要な時に必要な分だけクラウド上から調達することができます。
クラウド型AIサービスの特徴は、基盤となるインフラストラクチャやハードウェアの管理がサービスプロバイダーによって行われ、ユーザーはAIアプリケーションの開発や運用に集中できる点にあります。また、APIを通じた簡単な統合や、自動スケーリング機能によって、柔軟にリソースを拡張できるのも大きな特徴です。
ベアメタル型GPU搭載サーバーとは
一方、ベアメタル型GPU搭載サーバーとは、仮想化レイヤーなしに直接物理サーバーにアクセスできるホスティングサービスです。NVIDIA A100やH100などの高性能GPUを搭載した専用物理サーバーをレンタルまたは購入し、完全なコントロール権を持って利用できます。
ベアメタル型サービスでは、ハードウェアに直接アクセスできるため、仮想化によるオーバーヘッドがなく、GPUの性能を最大限に引き出すことが可能です。特に低レイテンシが要求される処理や、特殊なハードウェア最適化が必要なAIワークロードに適しています。
メリットとデメリット
クラウド型AIサービスのメリット
- 柔軟なスケーラビリティ:需要に応じて数分でリソースを拡張・縮小できます。大規模なトレーニングジョブを実行する際に、一時的に多数のGPUを利用できる点は大きな利点です。
- 初期投資の削減:高価なGPUハードウェアを自前で購入する必要がなく、従量課金制で利用できるため、初期コストを抑えられます。
- 管理の容易さ:インフラストラクチャの運用・保守はプロバイダーが担当するため、技術チームはAIモデルの開発に集中できます。
- 統合サービス:データストレージ、モニタリング、セキュリティなど、関連サービスと容易に連携できる統合環境が提供されています。
クラウド型AIサービスのデメリット
- 長期的なコスト増加:長期間・大規模な利用では、累積コストがベアメタル型に比べて高くなる傾向があります。
- パフォーマンスの変動:共有インフラストラクチャのため、「ノイジーネイバー問題」によりパフォーマンスが安定しない場合があります。
- カスタマイズの制限:ハードウェアレベルでの細かいカスタマイズや特殊なハードウェア構成の実現が困難です。
- データセキュリティと規制対応:機密データの処理や特定の規制要件への対応が難しい場合があります。
ベアメタル型GPU搭載サーバーのメリット
- 最大限のパフォーマンス:仮想化のオーバーヘッドがないため、GPUの能力を100%活用できます。特に大規模なAIモデルのトレーニングで差が出ます。
- 予測可能な性能:専用ハードウェアにより、一貫したパフォーマンスが保証されます。
- 高度なカスタマイズ:OSレベルからハードウェア構成まで、細かい設定やチューニングが可能です。
- 長期的なコスト効率:継続的に高いGPU使用率が見込まれる場合、長期的にはコスト効率が良くなる傾向があります。
ベアメタル型GPU搭載サーバーのデメリット
- 高い初期コスト:サーバーのセットアップや管理に関する初期投資が必要です。
- スケーリングの複雑さ:リソースの拡張にはハードウェアの追加が必要で、即時のスケーリングが難しいです。
- 運用負担:ハードウェア管理、セキュリティパッチの適用、障害対応など、運用負担がユーザー側にかかります。
- リソース利用の非効率性:使用率が変動する場合、余剰リソースが発生しやすく、非効率になる可能性があります。
ユースケース別の最適な選択
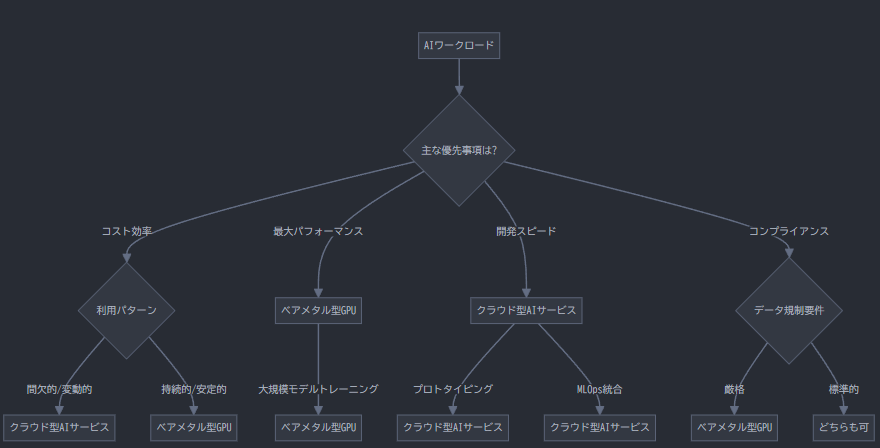
研究開発・プロトタイピング
研究開発やプロトタイピングフェーズでは、クラウド型AIサービスが適しています。短期間で様々なモデルアーキテクチャやハイパーパラメータを試す必要があるこのフェーズでは、クラウドの柔軟性と従量課金制の利点が活きます。Google Colaboratory、Amazon SageMaker Studio Labなどの環境を利用することで、初期コストを抑えながら迅速な実験が可能です。
実際、2023年のMLOpsコミュニティの調査によると、AIプロジェクトの初期段階では約78%の組織がクラウドベースの環境を活用しているというデータもあります。[参考:MLOps Community Survey 2023, https://mlops.community/mlops-survey-2023/]
大規模モデルトレーニング
大規模言語モデル(LLM)など、数十億から数兆のパラメータを持つモデルのトレーニングには、ベアメタル型GPU搭載サーバーが優れています。特にLLaMA、GPT、StableDiffusionなどの大規模モデルをフルスクラッチからトレーニングする場合、仮想化のオーバーヘッドがない環境で、最大限のGPU性能を引き出すことが重要です。
例えば、NVIDIA H100 GPU 8枚を搭載したベアメタルサーバーでは、同等のクラウド環境と比較して、トレーニング速度が15-25%向上するというベンチマーク結果もあります。[参考:NVIDIA Developer Blog, https://developer.nvidia.com/blog/]
本番環境での推論サービス
AIモデルの推論サービスを本番環境で提供する場合、ワークロードの特性によって最適な選択が分かれます:
- 安定した高負荷の推論サービス:一定の高いリクエスト量が見込まれる場合は、ベアメタル型GPU搭載サーバーが長期的なコスト効率とパフォーマンスの安定性の観点から優位です。
- 変動の大きい推論サービス:トラフィックの変動が大きい場合は、自動スケーリング機能を備えたクラウド型AIサービスが適しています。需要の変動に応じてリソースを動的に調整できるため、コスト効率が高まります。
規制要件の厳しい業界
金融、医療、政府機関など、データセキュリティやコンプライアンス要件が厳しい業界では、ベアメタル型GPU搭載サーバーまたはプライベートクラウドが適切な選択となることが多いです。特にGDPR、HIPAA、PCI DSSなどの規制に準拠する必要がある場合、データの所在と管理の透明性が重要になります。
現実的なアプローチ:ハイブリッド戦略
実際のAIプロジェクトでは、単一のアプローチではなく、ワークロードごとに最適な環境を選択するハイブリッド戦略が効果的です。例えば:
- 研究開発・実験:クラウド型AIサービスを活用し、迅速な検証を行う
- 大規模トレーニング:ベアメタル型GPU搭載サーバーで効率的なトレーニングを実施
- 本番推論サービス:トラフィックパターンに応じて、ベアメタルとクラウドを使い分ける
このアプローチにより、各フェーズで最適なコスト効率とパフォーマンスを実現できます。
まとめ
クラウド型AIサービスとベアメタル型GPU搭載サーバーは、それぞれに長所と短所があります。選択にあたっては、プロジェクトの要件、予算、技術的専門性、長期的な展望を総合的に考慮することが重要です。
特に日本国内では、クラウドサービスの高い信頼性と、ベアメタルサーバーを提供するホスティングプロバイダーの充実度を踏まえたうえで、最適な環境を選択することが求められます。最終的には、AIプロジェクトの成功には、技術的要件に合わせた柔軟なインフラ戦略が鍵となるでしょう。
本記事が、AI開発におけるインフラストラクチャ選択の指針となれば幸いです。ご質問やご意見がございましたら、コメント欄にてお気軽にお寄せください。